Background
This is the story of a project to add an efficient CPU backend for a shader language that is meant to compile down to GPU programs. Allow me to set the scene with a few prerequisite pieces of technology to become acquainted with:
The Forge Framework
The Forge is a cross-platform rendering framework that powers several notable games including Hades, Starfield, and No Man's Sky. It's designed to provide a consistent, high-performance graphics API abstraction across multiple platforms including PC, consoles, and mobile devices. One of its key features is the "Forge Shading Language" (FSL), which allows developers to write shaders once and have them automatically translated to the appropriate platform-specific shader language.
Intel's ISPC
ISPC (Intel SPMD Program Compiler) represents an interesting approach to CPU parallelism. It allows developers to write C-like code that gets compiled into SIMD-optimized instructions, effectively bringing GPU-style parallel programming to the CPU. The "Single Program, Multiple Data" (SPMD) model it uses is similar to how GPU compute shaders work - you write code as if it's running on a single element, but it actually executes in parallel across many elements using vector instructions.
What makes ISPC particularly interesting is its ability to:
- Achieve 3-6x speedups on modern CPU architectures without manual vectorization.
- Maintain a programming model that's familiar to C/C++ developers.
- Provide deterministic execution and easier debugging compared to GPU compute.
- Generate platform-specific SIMD code (SSE, AVX, NEON) automatically.
The goal was to extend The Forge's shader compilation pipeline to generate ISPC code, allowing compute shaders written in FSL to target both GPU and CPU execution. To test this approach, I implemented a signed distance field (SDF) generator that processes grayscale images to compute distance fields - a common graphics operation useful for everything from font rendering to special effects.
SDFs proved to be an ideal test case because they:
- Require significant parallel computation
- Have clear visual feedback for correctness
- Represent a real-world graphics workload
- Can benefit from different optimization strategies on CPU vs GPU
What started as a simple proof-of-concept led to some interesting discoveries about performance optimization, memory access patterns, and the unexpected benefits of ISPC's task system for parallel computation.
Test Environment and Limitations
All testing was done on an M3 Max MacBook Pro running macOS 14.0. While this provided a convenient development environment, it's worth noting some limitations of using this as a test platform:
- ARM's NEON SIMD instructions are limited to 128-bit wide operations, unlike AVX on x86 which can go up to 512 bits. This means we're likely not seeing the full potential of CPU SIMD acceleration.
- Apple Silicon's unified memory architecture means the GPU has direct access to system memory. On discrete GPU systems, we'd see additional overhead from PCIe transfers between CPU and GPU memory, which could impact the relative performance comparison.
- The M-series chips are technically "mobile" processors, so both CPU and GPU performance may not be representative of high-end desktop hardware.
These limitations mean the absolute performance numbers should be taken in context. The relative improvements from our optimizations are still meaningful, but running on different hardware (especially with wider SIMD support) could show even better CPU performance scaling.
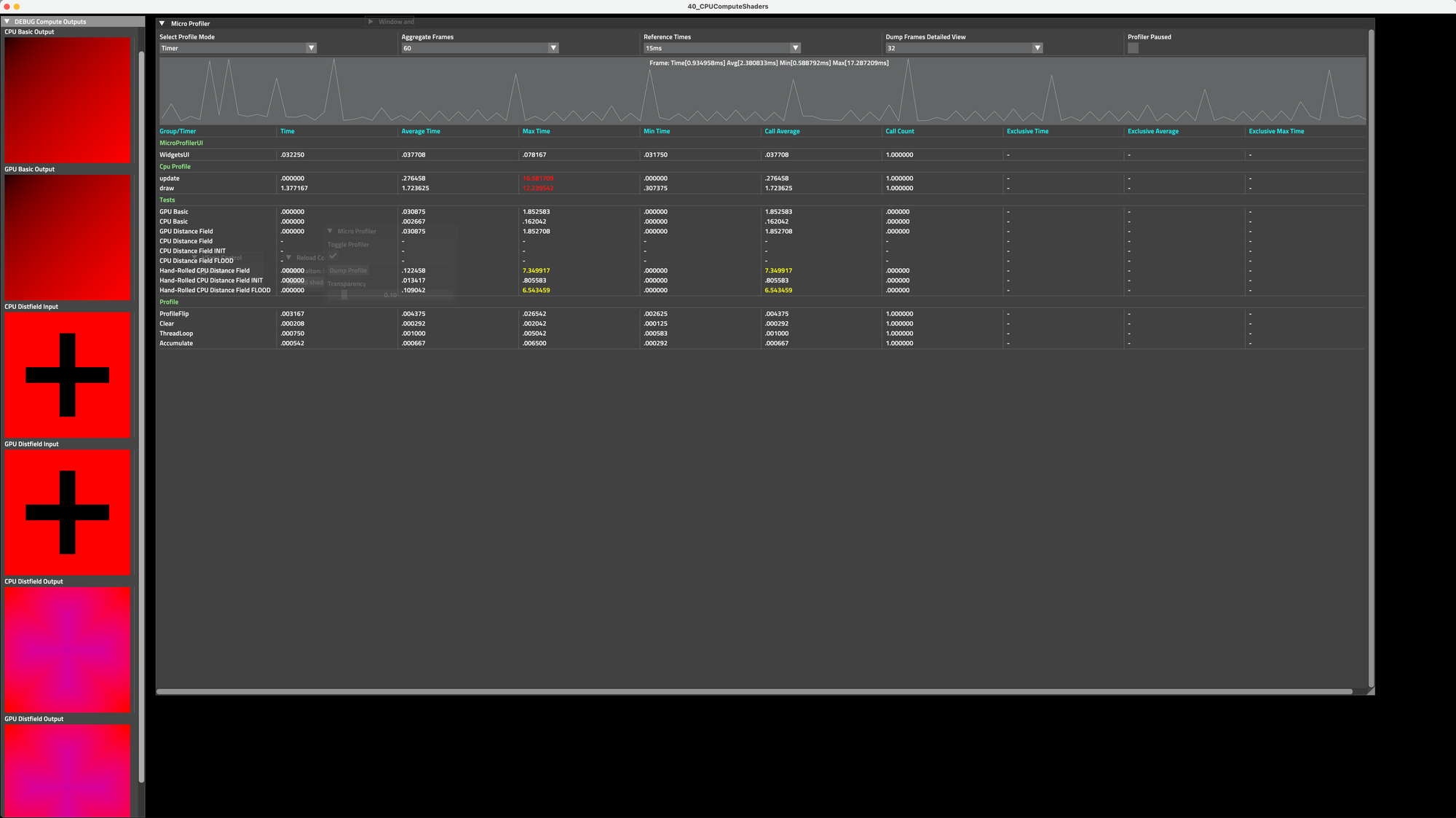
Technical Implementation Journey
The implementation journey followed an incremental approach, starting with basic validation before tackling the more complex SDF generation.
Initial Validation: Basic Compute Test
The first step was creating a simple compute shader that would help validate the ISPC code generation pipeline. I implemented a basic gradient generator that computed pixel colors based on screen coordinates. This shader served as an excellent test case because:
- The output was visually verifiable
- The computation was simple enough to debug easily
- It helped establish the basic infrastructure for CPU/GPU comparison testing
Moving to Distance Fields
With the basic framework in place, I implemented a signed distance field generator. The initial approach used a brute force algorithm:
- First pass identifies edges in the input image based on a threshold value
- Second pass computes the minimum distance from each pixel to the nearest edge
While this worked correctly, performance was poor:
- GPU version: ~30ms
- CPU version: ~8500ms
Jump Flooding Algorithm
To improve performance, I switched to the jump flooding algorithm, which takes a more efficient approach to distance field computation:
- Initial pass still identifies edges
- Multiple flood passes are then executed with decreasing step sizes
- Each pixel looks at neighbors at the current step size to find the closest edge point
- Final pass converts the closest edge positions into actual distances
This change resulted in a dramatic performance improvement:
- GPU version: ~1.4ms (down from 30ms)
- CPU version: ~35ms (down from 8500ms)
This required some interesting technical solutions:
Double Buffering for GPU Safety
One key learning was the difference between CPU and GPU memory access patterns. On the GPU, we needed to carefully manage buffer access to prevent race conditions where some shader invocations might read values before others had finished writing. The solution was to implement double buffering:
// Alternate between two seed buffers for read/write operations
for (int step = 8; step >= 0; --step) {
// Read from current buffer, write to other buffer
cmdBindDescriptorSet(pCmd, 0, pDistFieldFloodDescriptorSet[currentSeedBuffer]);
cmdDispatch(pCmd, groupSizeX, groupSizeY, 1);
currentSeedBuffer = 1 - currentSeedBuffer;
}
Interestingly, this wasn't necessary in the CPU implementation due to ISPC's stronger execution guarantees - all active SIMD lanes execute in lock-step within a given program instance.
Initial ISPC Generation
The first ISPC implementation followed the shader translation directly, but this proved sub-optimal. While it achieved good SIMD utilization (showing 100% lane usage in ISPC's instrumentation), it wasn't taking advantage of ISPC's more advanced features like task-based parallelism.
Performance Optimization
After getting the jump flooding algorithm working, I hit an interesting realization: I had tackled this project backwards. Instead of starting with the FSL-to-ISPC code generation (which was honestly a pain to debug), I should have first written plain ISPC code to understand how to make it fast. This would have made it much easier to figure out what the generated code should look like.
Hand-Written ISPC: A Fresh Approach
I decided to take a step back and write a direct ISPC implementation of the algorithm. The big breakthrough came from using ISPC's task system for multi-threading. Adding this was surprisingly straightforward - I just needed to create a layer of indirection between the entry point and the implementation, then use ISPC's launch[NUM_Y_THREADS] syntax to distribute the work. The only real infrastructure work was implementing three functions that let ISPC use The Forge's threading library to actually launch the threads.
This change alone brought the CPU execution time down from 35ms to around 5-6ms. Instead of running on a single core with SIMD, we were now using all available CPU cores, with each core still getting the benefits of SIMD execution.
Memory Access Patterns
Looking at ISPC's instrumentation output showed we were getting 100% SIMD lane utilization, which was great, but there was still room for improvement. The main bottleneck shifted to memory access patterns - specifically the scatter and gather operations where we had to pull data from different parts of memory into SIMD registers.
This is particularly visible in the flood implementation:
// This causes gather operations - not great for SIMD
int<2> seed = make_int2(gFloodSeedBufferIn[sampleSeedIdx],
gFloodSeedBufferIn[sampleSeedIdx + 1]);
// Later we need scatter operations to write results
gFloodSeedBufferOut[seedIdx] = closestSeed.x;
gFloodSeedBufferOut[seedIdx + 1] = closestSeed.y;
I tried reorganizing the memory layout to store X and Y coordinates separately (structure of arrays vs array of structures), but the performance gain was minimal - maybe 1ms if that. The nature of the jump flooding algorithm means we need to access memory in patterns that just aren't ideal for SIMD operations.
What I'd Do Differently
The biggest thing I learned from this project is the importance of prototyping the actual computation separate from the infrastructure around it. I spent a lot of time wrestling with FSL generation when I should have first figured out how to write efficient ISPC code directly. That would have made it much clearer what the generated code needed to look like.
Technical Insights
The project revealed some interesting differences between CPU and GPU implementations of parallel algorithms. The most notable insight came when implementing the jump flooding algorithm's multiple passes. On the GPU, we ran into an issue where shader invocations might read values before others had finished writing - a classic race condition. We needed to use double buffering, swapping between two seed buffers for the read and write operations of each pass.
But when implementing the same algorithm on the CPU with ISPC, everything just worked without this extra complexity. This isn't magic - it's because ISPC provides strong convergence guarantees. When you're running SIMD instructions, all active lanes execute together, and when control flow diverges, they reconverge as soon as possible. Since we're literally executing every statement at the same time with CPU SIMD instructions and masks handling control flow, we get this synchronization for free.
However, the CPU implementation faced its own challenges. While we achieved 100% SIMD lane utilization (meaning we were using all available vector processing capacity), memory access became our bottleneck. The jump flooding algorithm requires gathering data from different memory locations based on the current step size, then scattering results back out. These non-contiguous memory operations aren't ideal for SIMD, but they're inherent to how the algorithm works.
These kinds of tradeoffs are typical when working across CPU and GPU - what's trivial on one architecture might be challenging on the other. Having a unified way to target both through FSL and ISPC lets us choose the best platform for each specific use case, or even run the same algorithm on both for comparison.
Conclusion
This experiment in bringing GPU-style compute shaders to the CPU through ISPC proved more interesting than I initially expected. What started as a simple exercise in code generation became an exploration of parallel computing patterns across different architectures.
The jump flooding algorithm went from an 8.5-second CPU implementation to just 5ms by properly leveraging ISPC's task system - a pretty dramatic improvement for what amounted to a relatively small change in how we structured the computation. This really highlighted how the right abstraction (in this case, ISPC's task system) can make parallel programming significantly more approachable.
It also showed that unified shader languages like FSL can successfully target both CPU and GPU implementations, though you need to be thoughtful about the underlying architecture differences. Things like memory access patterns and synchronization requirements can vary significantly between platforms, even when the core algorithm remains the same.
While the GPU implementation was still faster for this particular workload (1.4ms vs 5ms), having the ability to run compute shaders on either CPU or GPU opens up interesting possibilities. You might choose CPU execution for better debugging, deterministic execution, or to better balance system resources. The key is having the flexibility to make that choice without rewriting your core algorithms.
Get Involved
The code for this project is open source on my fork of The Forge. If you're interested in CPU/GPU compute abstractions or want to experiment with ISPC and The Forge, feel free to check it out as it might be a good example to work from.
If you like this, consider subscribing for more stuff like this or reaching out on X where I am @joe_sweeney.